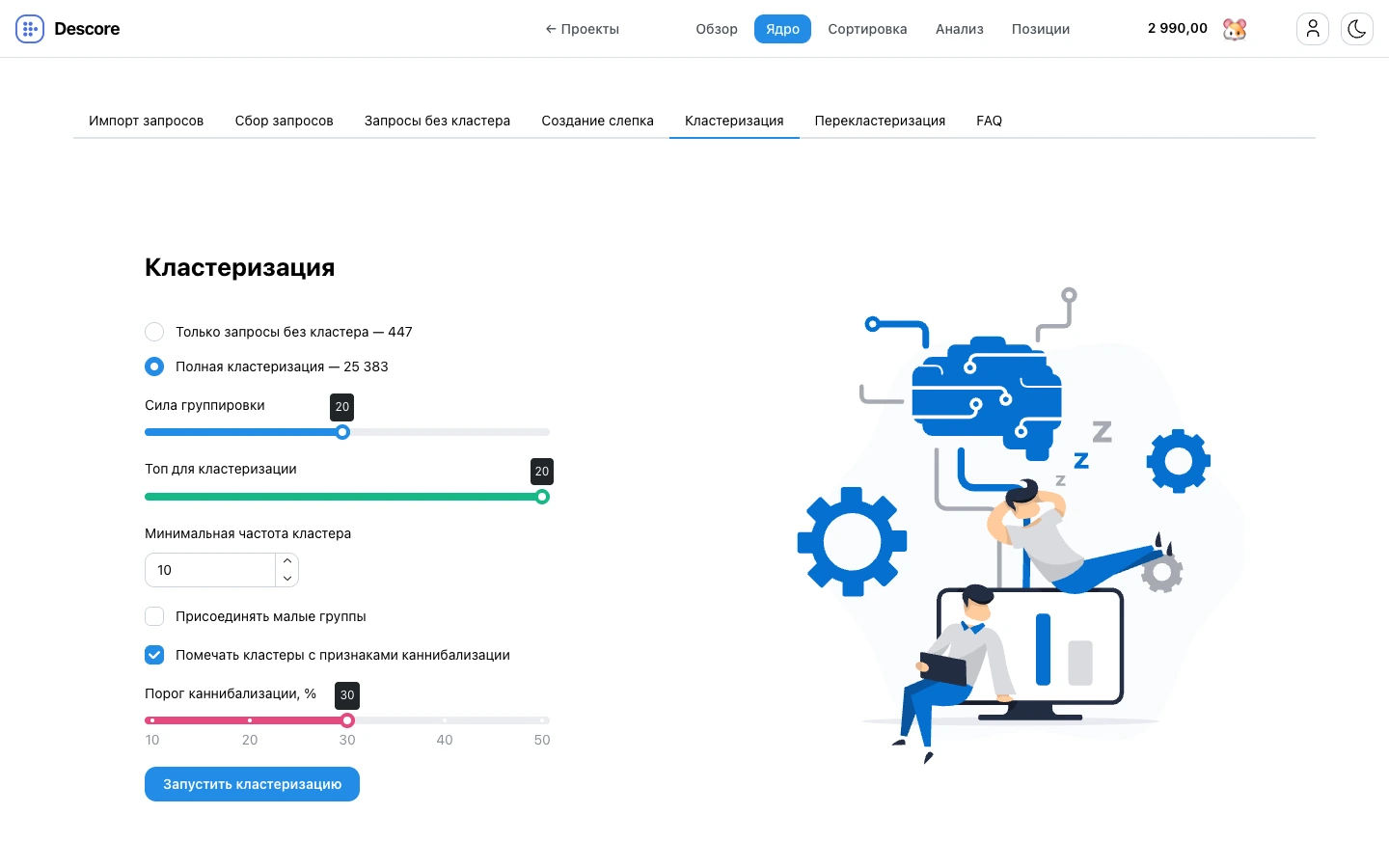
Кластеризация
Кластеризация семантического ядра по новому алгоритму
В Descore используется не Hard / Soft / Medium кластеризация, а современный алгоритм собственной разработки на основе поисковой выдачи. Он практически избавляет от ручной доводки и снимает самую утомительную часть: тысячи мелких решений при ручной разборке ядра, которые на больших проектах растягиваются на месяцы и годы.
Настройки
Возможности алгоритма
Алгоритм рассчитан на большие ядра до 500 000 ключей и работает от SERP-слепка: система сравнивает пересечения URL в ТОПе и группирует запросы по реальному интенту, а не только по похожим словам. Настройки помогают получить нужную структуру кластеров-страниц под конкретное ядро: можно регулировать глубину ТОПа и силу группировки, отсекать группы по минимальной частоте, присоединять малые группы и помечать кластеры с признаками каннибализации.
Что на выходе
Результат кластеризации
После кластеризации Descore превращает сырую семантику в иерархическую структуру, с которой уже можно работать: теги объединяют кластеры, каждый кластер собирает запросы вокруг будущей или существующей страницы. На уровне кластера видно суммарную частоту как спрос, а внутри - хвост запросов, посадочные и позиции. Можно раскрыть каждый кластер и оценить качество группировки по посадочным страницам каждого запроса.
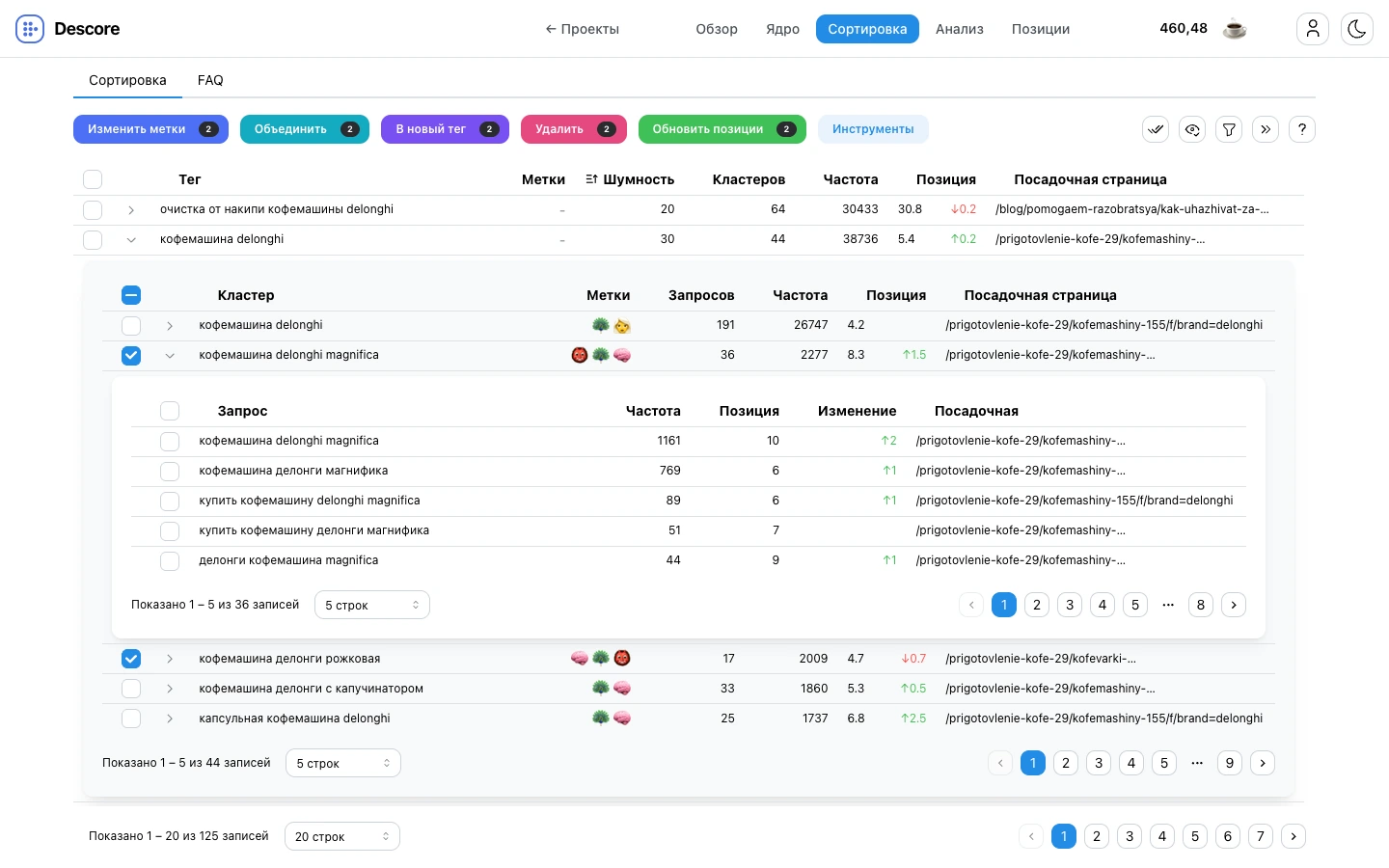
Посадочные
Индикатор качества группировки
В Descore посадочная всегда рядом со структурой: у тега, кластера и каждого запроса. Это не вспомогательный URL, а индикатор качества кластеризации и оптимизации страниц. Если запросы внутри кластера сходятся к одной посадочной, группа выглядит цельной; если URL расползаются, сразу видно повод проверить границы кластера, каннибализацию или саму страницу.
Теги
Верхний слой семантики
Тег в Descore — это не ручная метка, а автоматический результат работы алгоритма. После кластеризации система сравнивает поисковые сигналы и объединяет близкие кластеры в крупные группы. Внутри тега кластеры близки по выдаче, а между разными тегами остаются только слабые или случайные пересечения. Так ядро видно не россыпью отдельных групп, а смысловыми блоками.
Шумность
Очистка семантики
Алгоритм не только собирает структуру, но и рассчитывает шумность для каждого тега. Она показывает, насколько выдача по конкретному тегу отличается от остального ядра. Высокая шумность — это маркер для ревизии: так быстрее находятся чужеродные ветки, специфичные темы и участки семантики, которые стоит проверить глазами, прежде чем оставлять в общей структуре.
Сила группировки
Не режим, а сила группировки под сайт
Вместо выбора между Hard / Soft / Medium вы настраиваете силу группировки кластеризации под свою нишу и свой сайт. Для точной настройки доступны 40 ступеней: для интернет-магазина часто подходит диапазон 5-15, для услуг и контентных проектов - 15-25, для крупных медиа - 25-40. Сначала подберите силу на части ядра, затем запускайте кластеризацию всего проекта.
Сила группировки
ТОП кластеризации
Глубина ТОПа
Глубина ТОПа меняет оптику алгоритма. ТОП-10 — более строгий режим: система смотрит только на лидеров выдачи и собирает чистые, сфокусированные группы — чаще подходит для коммерции. ТОП-20 раскрывает больше граней выдачи и помогает уловить сложные связи между запросами, которые не всегда видны по первым результатам.
Топ для кластеризации
Минимальная частота
Порог полезного спроса
Вы сами определяете порог входа — с каким спросом есть смысл работать. Минимальная частота отсекает группы-пустышки, под которые невыгодно делать отдельную страницу. Так структура не раздувается от микрокластеров, и на рабочем столе остается только то, что реально пойдет в работу.
Малые группы
Баланс между чистотой и охватом
Присоединение малых групп регулирует баланс между строгой структурой и сохранением охвата. При включении микрокластеры, которые не прошли порог частотности, не отсекаются сразу: система пытается найти для них близкие крупные группы по выдаче. Если достаточно близкой связи нет, такие группы остаются шумом. Это помогает сохранить больше семантики, но требует осторожности: границы интента становятся мягче, и в кластер могут попасть спорные запросы.
Каннибализация
Устранение конкуренции внутри сайта
Метка каннибализации показывает кластеры, где поисковая видимость распределяется между несколькими вашими страницами. Порог каннибализации — это доля видимости, которая уходит не на главную посадочную кластера, а на другие URL. Если поставить 20%, система пометит кластер, когда второстепенные посадочные вместе забирают 20% или больше. Чем ниже порог (10-20%), тем чувствительнее проверка; 30% — сбалансированный режим; 40-50% покажет только явные случаи, где видимость сильно расползлась. Это четкий сигнал для ревизии: объединить страницы, разделить интенты или перераспределить запросы.
Порог каннибализации, %
Полная семантика
Почему важно загрузить всё ядро
Полное ядро нужно не ради размера, а для точности. Если дать алгоритму только верхушку ключей, он не увидит естественных границ кластеров и может потерять группы, где десятки НЧ-запросов суммарно дают больше спроса, чем один ВЧ-запрос. При этом загрузка полного хвоста не означает, что нужно постоянно мониторить позиции по каждому запросу. Структура строится по всей релевантной семантике, а для регулярного съема позиций в системе можно выбрать ключевые запросы внутри кластера — репрезентативную выборку без лишнего расхода.
История алгоритма
История одного ядра на 450k запросов
Descore не задумывался как очередной SEO-сервис. Всё началось с проекта, где нужно было адекватно разобрать огромную семантику. Проблема была не в объемах, а в тысячах мелких выборов: куда отнести этот запрос, нужна ли под него отдельная страница, как не допустить каннибализации.
Готовые сервисы выдавали базу, которую приходилось месяцами доводить руками. Нам это надоело. Мы сделали собственный алгоритм, чтобы система сама собирала логичные группы на основе выдачи, а SEO-специалист тратил время только на проверку спорных моментов.
Когда мы прогнали ядро и увидели, сколько времени это сэкономило, стало очевидно: мы должны снять эту боль и с других специалистов. Поэтому мы не остановились на одном алгоритме, а построили вокруг него удобную систему для работы со страницами-кластерами. Этот сценарий стал ориентиром по масштабу: кластеризация Descore поддерживает ядра до 500 000 запросов.
Путь запуска
Как провести кластеризацию
- Создайте проект под сайт или раздел.
- Импортируйте запросы или соберите семантику внутри системы.
- Перенесите запросы на кластеризацию.
- Создайте SERP-слепок для запросов из ядра проекта.
- Запустите кластеризацию и перейдите в сортировку.
Тарифы
Стоимость
Для автоматической кластеризации нужны две платные операции: сначала SERP-слепок по запросам ядра, затем расчет кластеризации.
В результате вы получаете не только группы запросов. При создании слепка система фиксирует позиции по всем запросам для вашего домена, а после кластеризации формирует срез видимости с 30 конкурентами для каждого кластера. Так вы получаете готовую структуру и данные для проверки выдачи без ручного разбора тысяч запросов в Excel.
1 лимит = 1 рубль. Стоимость одинакова на всех тарифах.